Upgrade Tesseract OCR: Difference between revisions
| (17 intermediate revisions by the same user not shown) | |||
| Line 15: | Line 15: | ||
<li>Rename the tesseract folder present in our installation to tesseractOLD<br> | <li>Rename the tesseract folder present in our installation to tesseractOLD<br> | ||
eg: C:\LogicalDOC\tesseract will become C:\LogicalDOC\tesseractOLD</li> | eg: C:\LogicalDOC\tesseract will become C:\LogicalDOC\tesseractOLD</li> | ||
<li>download the file to the following address https://service.logicaldoc.com/tesseract/tesseract41-win.zip</li> | <li>download the file to the following address https://service.logicaldoc.com/tesseract/4.1.0/tesseract41-win.zip</li> | ||
<li>extract the contents of the archive into the folder where you installed LD eg: C:\LogicalDOC</li> | <li>extract the contents of the archive into the folder where you installed LD eg: C:\LogicalDOC</li> | ||
<li>This package already includes optimized dictionaries for English, French, German, Italian and Spanish languages.<br> | <li>This package already includes optimized dictionaries for English, French, German, Italian and Spanish languages.<br> | ||
If you need other languages you can download them from the following address https://tesseract-ocr.github.io/tessdoc/Data-Files | If you need other languages you can download them from the following address https://tesseract-ocr.github.io/tessdoc/Data-Files.html<br> | ||
download the files and put them in the \tessdata folder</li> | download the files and put them in the \tessdata folder</li> | ||
</ol> | </ol> | ||
| Line 27: | Line 27: | ||
<li>check the availability of tesseract 4.1 and install it<br> | <li>check the availability of tesseract 4.1 and install it<br> | ||
Note: in the latest versions of Ubuntu this is already available also for many versions of Linux Debian and CentOS it is possible to use packages already available. <br> | Note: in the latest versions of Ubuntu this is already available also for many versions of Linux Debian and CentOS it is possible to use packages already available. <br> | ||
For more information: https:/ | For more information: https://tesseract-ocr.github.io/tessdoc/Installation.html</li> | ||
<li>check the configuration of Tesseract OCR in LogicalDOC by | <li>check the configuration of Tesseract OCR in LogicalDOC by verifying that it points to the path of tesseract command.<br> | ||
The complete path to the configuration in the LogicalDOC GUI interface is: Administration, Settings, OCR, field path | |||
<gallery> | |||
File:Logicadoc-ocr-settings.png|OCR Settings in LogicalDOC 8.4.2 | |||
</gallery></li> | |||
<li>don't forget to install the language dictionary packages. These may already be available as installable packages<br> | <li>don't forget to install the language dictionary packages. These may already be available as installable packages<br> | ||
eg: the following will install the japanese dictionary on Debian Buster | eg: the following will install the japanese dictionary on Debian Buster | ||
<pre> | |||
apt-get install tesseract-ocr-jpn (installs japanese dictionary) | apt-get install tesseract-ocr-jpn (installs japanese dictionary) | ||
</pre> | |||
or perhaps you will have to download the language files | or perhaps you will have to download the language files into the /tessdata folder<br> | ||
Get dictionaries packages from https://tesseract-ocr.github.io/tessdoc/Data-Files.html</li> | |||
</ol> | </ol> | ||
=== Additional information === | |||
* [https://tesseract-ocr.github.io/tessdoc/ Tesseract documentation] | |||
* [https://qiita.com/aki_abekawa/items/418e069038fbdb77c59e Re-learn Japanese with Tesseract 4.1 using LSTM]<br> | |||
[[Category: Tesseract]] | |||
[[Category: OCR]] | |||
Latest revision as of 11:08, 2 December 2021
Starting from LogicalDOC 8.3.4 tests were carried out on a new version of the integrated OCR Tesseract.
More precisely, tests were conducted on version 4.1 of Tesseract.
This new version is much more precise in text recognition and also faster, so with a very simple action you will get 2 important benefits:
a faster OCR recognition that uses less system resources and above all better quality in character recognition.
Note: the version of Tesseract 4.1 that we propose to install is perfectly compatible with LogicalDOC starting from LD 6.8.4
Starting from LogicalDOC 8.4.1 this is the version that is distributed by default, so if you have installed your system in version 8.4.1 or 8.4.2 you don't need to upgrade
Windows systems
The change is very simple, let's talk about a simple replacement
- Rename the tesseract folder present in our installation to tesseractOLD
eg: C:\LogicalDOC\tesseract will become C:\LogicalDOC\tesseractOLD - download the file to the following address https://service.logicaldoc.com/tesseract/4.1.0/tesseract41-win.zip
- extract the contents of the archive into the folder where you installed LD eg: C:\LogicalDOC
- This package already includes optimized dictionaries for English, French, German, Italian and Spanish languages.
If you need other languages you can download them from the following address https://tesseract-ocr.github.io/tessdoc/Data-Files.html
download the files and put them in the \tessdata folder
Linux systems
- remove tesseract if previously installed
- check the availability of tesseract 4.1 and install it
Note: in the latest versions of Ubuntu this is already available also for many versions of Linux Debian and CentOS it is possible to use packages already available.
For more information: https://tesseract-ocr.github.io/tessdoc/Installation.html - check the configuration of Tesseract OCR in LogicalDOC by verifying that it points to the path of tesseract command.
The complete path to the configuration in the LogicalDOC GUI interface is: Administration, Settings, OCR, field path-
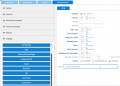 OCR Settings in LogicalDOC 8.4.2
OCR Settings in LogicalDOC 8.4.2
-
- don't forget to install the language dictionary packages. These may already be available as installable packages
eg: the following will install the japanese dictionary on Debian Busterapt-get install tesseract-ocr-jpn (installs japanese dictionary)
or perhaps you will have to download the language files into the /tessdata folder
Get dictionaries packages from https://tesseract-ocr.github.io/tessdoc/Data-Files.html
